Cette addon a été supprimé de Chrome Store parce qu'ils vont forcer à passer au Manifest 3.0 et de toute facon les anciens addons ne seront plus compatibles, ca me demanderait trop de temps de changer nombre de fonctions (dont les fonctions réseau pour charger les pages, tester si elles ont déjà été sauvées, etc) de l'addon parce que Google a décidé de changer la syntaxe de certaines fonctions pour faire croire que c'était pour la sécurité, et comble du comble des fonctions indispensables comme avoir les infos du tab dans lequel un script est injecté (utilisé par mon addons pour savoir quel est l'état de la page par exemple, en train de sauver, terminé, etc) seront apparemment supprimées aussi... Leur but semble étre en réalité de ne plus permettre aux utilisateurs de pouvoir choisir quoi que ce soit (Et oui vous ne revez pas google ose faire la morale sur l'acces aux données utilisateurs, dans les infos sur le manifest V3 ils osent meme dire que les fonctions réseau de l'addon donne un acces excessif au données utilisateurs, résultat un addon ne pourra plus rien faire, les outils de blocage de scripts et de pubs seront bien sur impactés...).
Download Addon Source File :
Pour installer cet addon, il faut activer le mode developper dans les pages des addons/extensions (compatible avec les navigateurs Chromium comme Edge), dézipper le fichier dans un dossier et charger ce dossier dans le navigateur depuis le bouton pour charger un addon localement une fois le mode développer activé.
Attention: Ce code n'avait jamais été prévu pour etre disponibles à tous, il est difficile à comprendre et n'était donc pas prévu pour être modifié par d'autres, mais pour l'utiliser il suffit de le charger dans le navigateur comme indiquée ci dessus.
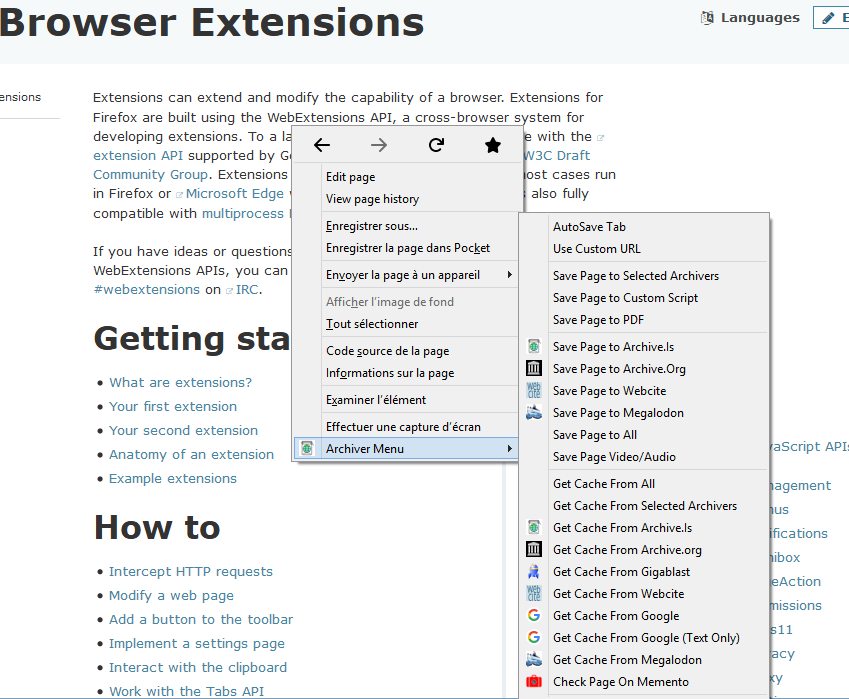
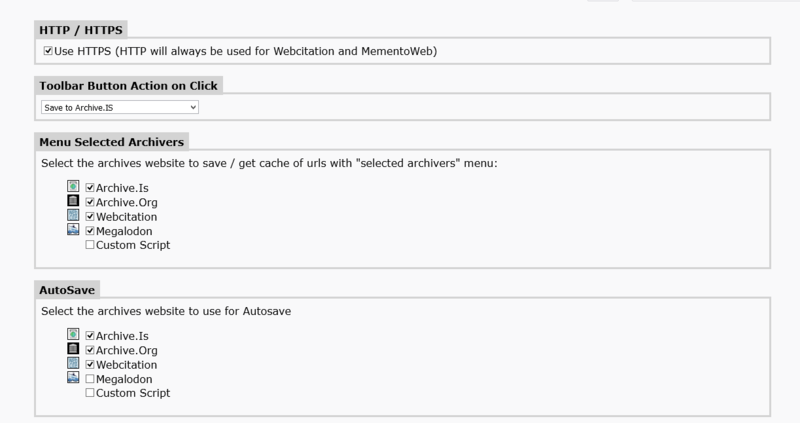
Archiver facilement les pages web avec les sites connus d'archives, en fichier pdf, en local, avec des options pour les menus, sauver automatiquement les tabs, fenetres, ou suivant les urls, etc.
Exemples d'options :
- Sauver un fichier ou une page localement
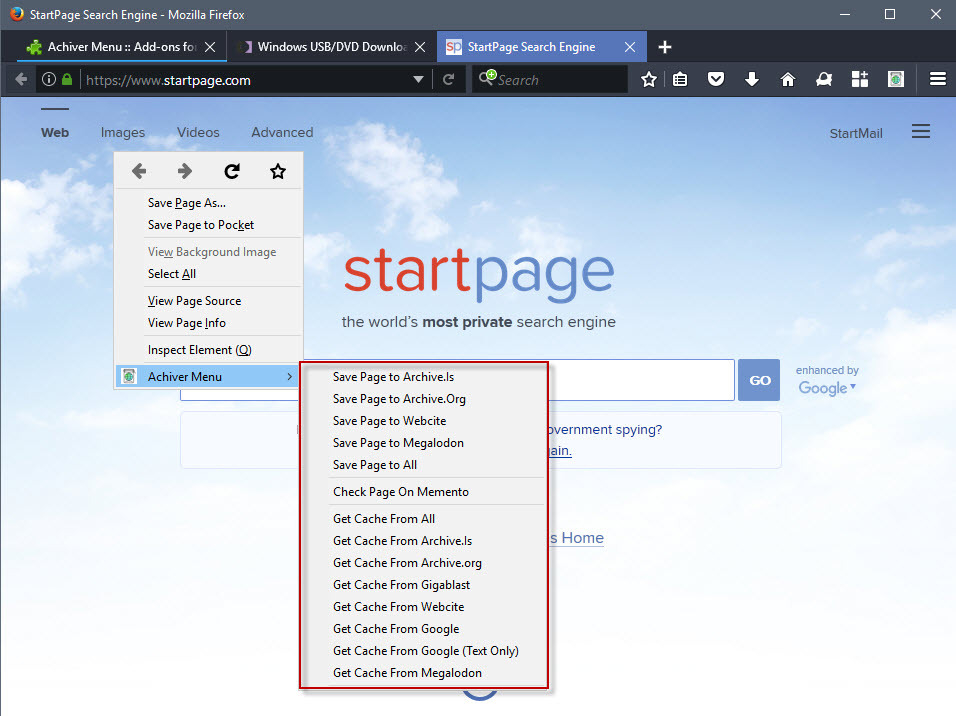
- Sauver ou voir les pages archivées sur archive.org, archive.is, webcitations.org, megalodon.jp, google cache, gigablast.comou tous en meme temps, depuis la version 1.4.6 les pages sauvées sur archive.is et megalodon sont automatiquement mises à jour si elles existent déjà.
- Depuis la version 1.8: Ajoutez votre propre service d'achive si compatible.
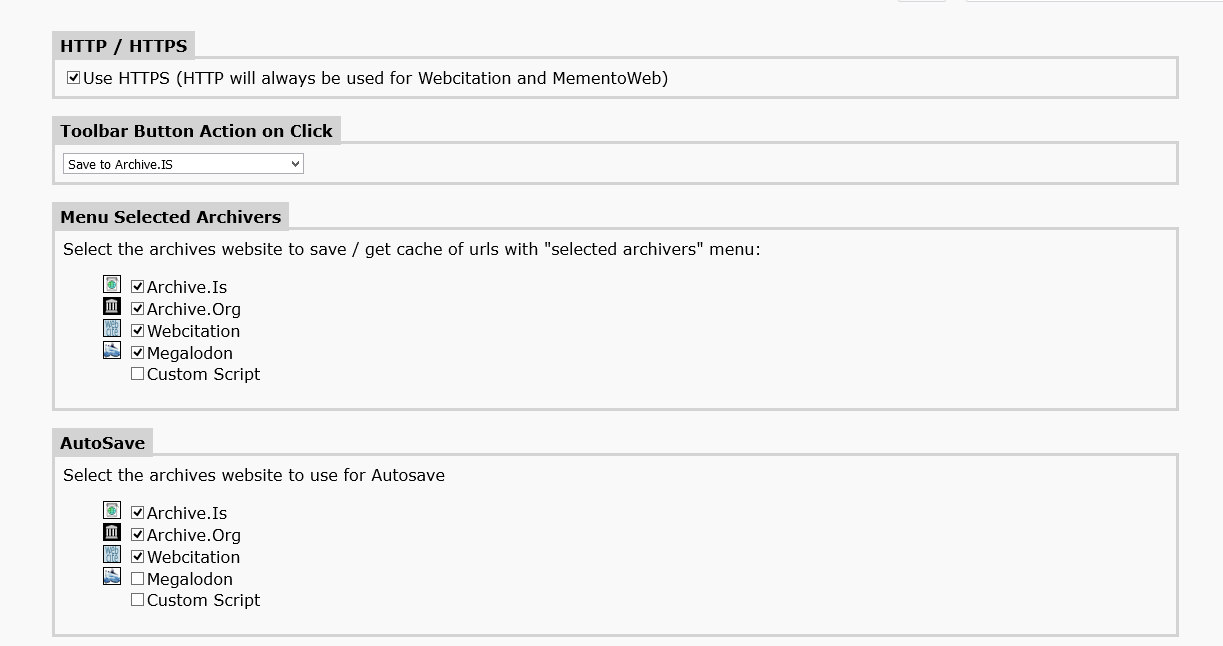
- AutoSave Tab: Activer le menu et le tab selectionné sera automatiquement archivé suivant les options choisies dans la section correspondante des options.
- Sauver un lien dans une page, une image, une frame, etc.
- Selectionner du texte sur une page et sauver tous les liens sélectionnés, même les liens en texte sans tag A.
- Menus et différentes options pour choisir les sites d'archives à utiliser
- Options pour personnaliser les options de sauvegarde avec un masque d'URL comme http://www.website.com/* pour sauver toutes les pages de www.website.com
- Vérifier une page ou un lien sur http://timetravel.mementoweb.org/
- Options pour sauver automatiquement un bookmark de la page lors de la sauvegarde d'une page.
- Sauver les videos en un click.
- Rechercher le texte selectionné dans une page sur archive.is, archive.org, search.yacy.net, gigablast.com,etc.
- Sur une page 404, il suffit d'utiliser le menu pour voir la version en cache du site d'archive que vous voulez.
- Utiliser votre propre script Javascript pour sauver les page
- Article: https://www.ghacks.net/2017/06/06/archiver-menu/
Moteur de Recherche personnalisé pour chercher dans différents sites d'archives (archive.org, sites web, archives de pdf, de livre, de journeaux, etc) utilisé par la fonction recherche dans le menu de l'addon:
Faite une Donation:
Si vous voulez télécharger localement un site en entier, utilisez par exemple le logiciel HTTrack:
Envoyez le lien sur les réseau sociaux ou ailleurs de la page de l'addon:
Version Chrome:
Version la plus récente (2.0.5) :
Télécharger :
- Version: 2.0.5
- Version: 2.0.0
- Anciennes / Autres Versions :
Versions :
Version 2.0.5
- solved problem with autosave urls and detection of archive.is already saved page option
Version 2.0.4
- problem with autosave urls and check if already archived: some pages done were not removed from the list
- problem with autosave urls on archive.org and urls with ?= solved
- when archiving to archive.is loading page will NOT be loaded until fully saved to save bandwith, it will display a simple loading state page
- when saving a video, the file will be in Defaut Download folder / Archived Videos / www.hostname.com / file
- when saving a video and option save webpage with video activated, the page will be saved in the same folder than the video in mhtml
- desactivated menu by defaut to save to webcite and to archive.Is Zip because the functions don't work on the website since months
- add menu to save screenshot of visible area of active page, it will be saved to same folder of the webpage in PNG.
- add random timout when saving to megalodon.jp to avoid robot protection
- research changed, now open new page and search by defaut on a google custom search engine with mulitple archive websites
- Save to Pdf enabled again on a new website
Version 2.0.3 (23/03/2020)
- changed defaut icon format for chrome compatibility
Version 2.0.2
- removed debug popup from savevideo page
Version 2.0.1
- options to set archive.is domain to use
- fixed memento problem with some date/time
- fixed a problem with frames when saving to local mode
- add option in archive page when saving a page to block loading of image and object to save bandwidth (always actived when using autosaveurls)
- add options to use new archiveorg save system [archive.org removed for non members the possibility to save links and screeshot of the page before release of this update !]
- changed defaut icon & add option to change the toolbar icon
- problems in some case of Auto archive resolved
- options to reuse tabs already opened for archiving set to true by default
- more options added to save from bookmarks and now work from "view all bookmarks" window (firefox) [Firefox version is not available for this release]
- save selection of links from a local file opened in browser now work
- bug resolved in some case with autosavetab options, opening multiple windows if not necessary
- when saving to local, it will try to get the files in the css (url: background, fonts, etc)
- solved a problem with reuse of tabs when button click with multiples options
- when saving to local file , the cache option to get the file from server is now set to default instead of none
- when saving to locale file a webpage, changed how long filename are truncated for better compatility with very long filenames
- in autoarchive, local file will not be saved (if you set *.pdf to save, a file like file:///localdisk/folder/data.pdf will NOT activate autoarchive options)
- problem with urls with parameters (?=xxx) when detecting urls for autosave or saving to local file, urls with ?= are detected (if you set *.pdf urls for autosave, urls like *.pdf?=xxxx will be detected )
- when saving to local, bug solved when problems with certains urls caused files not saved to local file
known problem: when using save to local file, sometimes some files are still not saved with the correct extension, but the parameter send to the download function is ok
- changed defaut video downloader, video download can take 10 sec or more to automatic download file
- save links popup updated with more options to save links
- in search, added a custom google search engine searching on archive websites (archive.org, archive.is and other like newspapers archives, pdf archives, ...): https://cse.google.fr/cse?cx=011864555441808463905:88ua9cbevzn
- add menu to save video from a link
- remove option to save pdf, the website is no longer really free (allow now only 5/6 urls only)
Version 2.0.0
- updated for google chrome compatibility
- added option autosave list of url at startup in the popup of autosaveurl
- when getting local cache, it display the local url of archived files for the host too
- with chrome, the get local cache menu will open directly the local folder in the browser
- resolved problem with save video and problem with url parameter of the video
- default domain for archive.today set to archive.is
- in firefox, save selectedlinks with selected text in textarea works
- add options when autosave list of urls to save only urls not already archived (use to add only new articles from rss/homepage or only new pages from sitemaps)
- with autosave list of urls, no images or big data (object, etc) will be loaded in browser page, to avoid bandwith usage (it's does not change the archived page on the archive website, it will be saved normally)
- resolved problem with add links without popup: the last urls of links and first of already saved urls in autosave list are now separated and saved correctly
- add options to add list of urls to save at startup like using "save links without popup" menu (if there's frames in the webpage, frames will be loaded and links of the frames added too ).
- add save links for a link (when click on save Links of Link, the linked url and the links in this linked webpage will be added to autosaveurls list)
- added menu to open sitemap.xml of the website of the page (in autosave menu)
Version 1.9.9
Released Jun 27, 2019 - 672.8 KB
Works with firefox 68.0a1 and later, android 68.0a1 and later
- add option to not display any notification when auto save urls list
- add option to autosave at startup for auto archive urls in options
- get cache from local in get page cache menus
- changed yacy search server to yacy.searchlab.eu
- when save a page to local if a video from a VIDEO src or source tag is downladed it's shown in downloads (to cancel if needed)
- better support when local download for tags source and srcset
- add option in autosave urls to save bookmarks or not only for autosaveurls ( by default: it will not save bookmarks for autosaveurls)
- when an opened webpage is saved to local file ,it will use the source code of the current visible page and not reload from server (known problem: the headers will not be saved)
- when save to local file with websitemode, the protocol (http,https,...) is added to filename
- when a file is save to local , the search terms (the parameters "?=" ) are added to page filename
- when bookmarking main url, the host name is not in the title because its already the folder name
- saveitoffline replaced by keepvid, because server is down
- firefox privacymode: if allow private mode not allowed all downloaded files for html pages will be shown in downloads
- added website save mode for frame
- when a url for autoarchive is set in options, use CTRL or mouse right click when saving the url will use the normal menu (in contexte menu and toolbar icon menu) and not use the predefined set for this url
- save to pdf use an external website to automatically save the pdf to local file in defaut folder (download will be shown in downloads list of browser)
Version 1.9.8
Released Mar 22, 2019 - 541.25 KB
Works with firefox 63.0 and later, android 63.0 and later
- add information on the saved local page (original url, saved date time, etc)
- add websitemode to save page to local file: the main folder will be the website domain and it will not save a copy of each needed file of a page for each page but do like in the website, and links of the page will by defaut set to the local saved page url (even if no local file is saved now, but you can save it later), it will be save in "defaut download folder / Archived Websites"
dont use it if you want easily share page, use save to local file classic mode instead
- solved bug with some pages (and integrated frames) when saving to local file
- add save to archivezip & websitemode to save list of urls
- defaut domain of archive.is set to archive.today
- added save archiveis zip and websitemode to save tabs options
- added autostart option in autosave menu: when checked, it will automatically start the archiving of the urls when opening browser
Version 1.9.7
Released Jan 20, 2019 - 538.83 KB
Works with firefox 63.0 and later, android 63.0 and later
- New option to set a shortcut key for toolbar button action
- With archive.is new option to save to local file the zip of archived page of archive.is
- New menu to save to archiveis and download automatically the zip archive file made by archive.is
- Better compatiblity with archive.is others domains when automatic redirection
- When a local archived page need files (like pictures, stylesheet, etc), the page will now be in a folder of the name of the main htm file and the others files in subfolder (before only needed files where in subfolder) to more easily share the saved page and the file needed to render the page, just copy the folder where is the html main file
- New menu to save selecteds links without popup like all page links
- Tab of archivers now open next to the archived page tab
Version 1.9.6
Released Nov 7, 2018 - 534.42 KB
Works with firefox 63.0 and later, android 63.0 and later
- Solved bug with bookmark autosave with some options configurations.
Version 1.9.5
Released Oct 4, 2018 - 534.29 KB
Works with firefox 63.0 and later
- minimum version of firefox set to 63.0
- removed pdf options: changed to autoarchive option to set preference for any url type
- changed url bookmark name: Archived URL is now at the end of the title (to search in bookmarks for archived urls, juste use "archived url" with your search words)
- add archiver menu to bookmarks
- fixed some problems with url protocols
- added wikiwix to get page cache
- in bookmarks, when bookmarking a page and the original page url is already bookmarked, the archived(s) url(s) are bookmarked just after the original page url.
- in bookmaks urls original urls page is titled with (Original) at the end and urls or archives with (Archive)
Version 1.9.4
Released Aug 30, 2018 - 407.74 KB
Works with firefox 58.0 and later, android 58.0 and later
- Fixed some minor translation errors
- Add options to use multiple action when click on toolbar button
- Add naver to get cache
- Add option to add urls to auto archive
- Add aliexpress partner link
- Add option to select pdf extension file
- Add option to auto save pdf when opened in browser
- Add option to save pdf files to special directory to easy find them
- Added date and url to source page or page saved to local file
- Add menu to save all tabs urls from a window
- Changed option page design
- Add option to save links of page without opening the popup
- Resolved problem with auto bookmarks when a bookmark cause an error now it continue to save other bookmarks
Version 1.9.3
Released Jun 27, 2018 - 443.17 KB
Works with firefox 58.0 and later, android 58.0 and later
- custom save video url can be set to local app protocol (other than http/https)
- added save page links menu for frames
- added save page links for selection
- added ebay with partner link in menu and option to use automatic partner link when navigate on ebay website
- added share menu options
Version 1.9.2
Released Jun 17, 2018 - 424.18 KB
Works with firefox 58.0 and later, android 58.0 and later
- bug solved with some browser button menu items not working
Version 1.9.1
Released Jun 15, 2018 - 424.07 KB
Works with firefox 58.0 and later, android 58.0 and later
- start code change for compatibility with google chrome
- bug solved when the only option to bookmarks was set to get cache, the url was not saved
- bug solved google text not shown when using custom archivers options in some case
- bug solved when using save page links on page with frames: it opened a popup by frame
- added goodgopher / webcite / megalodon.jp to search menu
- add option to show/hide save video/audio menu item
- add save to local option to autosave tab and custom archivers
- save page links compatible with text only links (in a sitemap for sample)
Version 1.9.0
Released Jun 8, 2018 - 355.84 KB
Works with firefox 58.0 and later, android 58.0 and later
- add options to save pages and files to local file
- add option to disable https for the session only
- add option to save a list of urls in AutoSave Menu
- add otion to save a bookmark when getting cache page
- pdf options by defaut to all archiver and to local
- save to pdf menu moved to save page group menu
- added more options to select displayed menus
- bug with encodeuri/decodeuri and malformed urls: now if a url is malformed, encode/decode is skipped instead of making error
- added Arquivo.pt to list of archivers to get cache
- added search menu to normal menu, select an archiver in menu and when click it will display a text to search, if a link is selected, it will search for the displayed text of the link
- when using autosave urls list, when the final archived page is loaded in browser, the page stop load in browser to save bandwith
- in option page, added button to save to txt the list of urls archived for this session (it save the original url, not the archive url on archive website)
- search menu icon: https://www.iconfinder.com/icons/118797/search_system_icon
- icon for menu save page links: https://www.iconfinder.com/icons/71801/delete_link_icon
- icon for file menu: https://www.iconfinder.com/icons/326639/download_file_icon#size=512
Version 1.8.0
Released Apr 10, 2018 - 245.62 KB
Works with firefox 58.0 and later, android 58.0 and later
- changed name to "Page Cache Archiver"
- add option to add custom url for archiver or other service
- added exalead to get cache
- added memento to get the most recent page cache from archivers
- when encodeuricomponent NOT enabled for a host, it use decodeuricomponent for the parameter
- bug solved: when saving a page of archiver to another archiver, the autoupdate don't work
- internal code change and simplifications
- use of http://favicon.yandex.net/favicon/ to display user added archivers favicon
- added autosave tab and autosave window to options for toolbar button
- bookmark name of archivers pages use hostname of archiver instead of a name
- minimal version updated to ff58
- changed menu name in english to shorter name for more visibility
Version 1.7.0
Released Mar 1, 2018 - 229.14 KB
Works with firefox 57.0 and later, android 57.0 and later
- menu option to display archivers menu like sub menu
- autosave work with frames: when only a frame change and not the tab url, it save the new frame url
- added options to customize file extension like pdf
- webcitation defaut email set to: webcite@email.com
- pdf option now work with save selection context menu
- add save to video/audio menu option to toolbar button options
- added option to save on script for frame
- added menu save to all for selection
- bug solved: with autosave autosaving a frame loading in the page like youtube embed player in some case
- bug solved: when saving archived page bookmark, it saved the url to save the page instead of the archived page
- bug solved: with selection of archiver, script was not launched if selected
- bug solved: for some urls, encodeuricomponent needed but not work with saveitoffline and archive.org
- changed menu names in french (more visibility)
- new icons:
- https://www.iconfinder.com/icons/7587/adobe_file_pdf_icon
- https://www.iconfinder.com/icons/282462/script_icon
- https://www.iconfinder.com/icons/34637/archive_icon
- https://www.iconfinder.com/icons/40681/archive_icon
- https://www.iconfinder.com/icons/40881/video_icon
- https://www.iconfinder.com/icons/49273/page_web_icon
- https://www.iconfinder.com/icons/10447/chain_link_web_icon
- https://www.iconfinder.com/icons/64917/selection_transform_icon
- https://www.iconfinder.com/icons/3719/image_icon
- https://www.iconfinder.com/icons/1084546/frame_notification_icon
Version 1.6.0
Released Dec 28, 2017 - 101.41 KB
Works with firefox 57.0 and later, android 57.0 and later
- Added option to save custom url
- Added pictures to menu
- Save bookmark now in folder host name
- In the bookmarks, when saving multiples urls, the archiveds urls of a url are directly below the url
- Save custom script option to work with frames, links, images, selection
- Option to save page in pdf , option added to button click defaut action
- Https allowed for webcitation (check browser https status for more infos)
- Minimum version of firefox changed to 57.0
- New option page design
- Added submenu to tab-strip
- Changed bookmark name display: when a url is used as name for bookmark (like with save link), it dislay the path without the hostname
- Fixed some bookmark title problems
Version 1.5.0
Released Sep 16, 2017 - 41.07 KB
Works with firefox 52.0a2 and later, android 52.0a2 and later
New Menus Options:
- get cache from custom archivers
- get cache from selected links
- save selected links to custom
- options to select archivers displayed in menu
- toolbar button option get cache from x archiver
- save video option changed to customised archivers
- new function to reuse tabs already opened by extension instead of create new on each time
- bug fixed : defaut folder for archived url now is NOT created when all options to bookmarks urls are set to false
- archiving of page maybe speeder in some case with big page and/or slow connections for archive.is and megalodon when auto updating/saving page
Version 1.4.9
Released Aug 17, 2017 - 38.32 KB
Works with firefox 52.0a2 and later, android 52.0a2 and later
- Minors Changes in Menu name for Memento
- Save Video now in save page menu group
- Get page cache menu displayed for the page main url when click on a frame and not only for frame
- corrected a bug with bookmarks and script in some rare situations
- Auto update of archived page on archive.is and megalodon now more speed.
- New Autosave Fonction: Select "Autosave" on a tab from menu and when the tab url change, the new page will be automatically saved to archivers selected in options for "autosave". But it don't work with frames currently.
Version 1.4.8
Released Jul 25, 2017 - 34.49 KB
Works with firefox 52.0a2 and later, android 52.0a2 and later
- Better compatibility with frames for menu "save selected links to"
- Menu to save page open too when click in a frame
- Memento link now in "get cache from" menu
Version 1.4.7
Released Jul 13, 2017 - 33.66 KB
Works with firefox 52.0a2 and later, android 52.0a2 and later
- Add option to add launch of custom script when saving main page (don't work with links, images, selected links, ...)
Version 1.4.6
Released Jul 8, 2017 - 32.47 KB
Works with firefox 52.0a2 and later, android 52.0a2 and later
- Archive.is now autoupdate to save the last version of the page
- Megalodon automatically save the page now and not only open the page to save it manually
Version 1.4.5
Released Jul 4, 2017 - 31.28 KB
Works with firefox 52.0a2 and later, android 52.0a2 and later
- Select text on the page and save all the links and even urls in the text without A tag.
- Menu and Options to Select the Archivers to Use to Save Webpage.
- Menu for "Saveitoffline" now display on the webpage and not only when click on media player.
- Added Javascript "strict" mode.
Version 1.3.4
Released Jun 20, 2017 - 26.75 KB
Works with firefox 52.0a2 and later, android 52.0a2 and later
- Tested with Firefox 52.0a2 (It seem the only bug is the right click menu of toolbar button is not displayed).
- Option to Automatically Save Archived Urls in Bookmarks.
- Save Video in One Click With saveitoffline.com .
- Internal Code Changes.
Version 1.2
Released Jun 12, 2017 2
Works with firefox 53.0 and later, android 53.0 and later2
- Translated to French
- Added more search engine to "search" menu when a text on the page is selected
- When using "Get Cache From All", now open a memento webpage too.
- Right Click on button item open now the 4 "Save as" items, "Save to All" and "Get Cache From All"
- Some code change, maybe a little faster.
Screenshots:
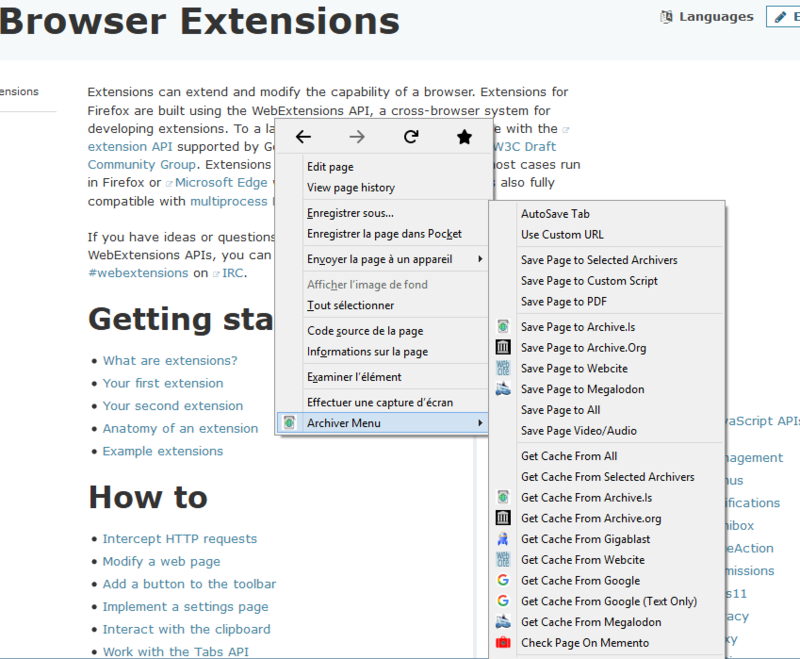
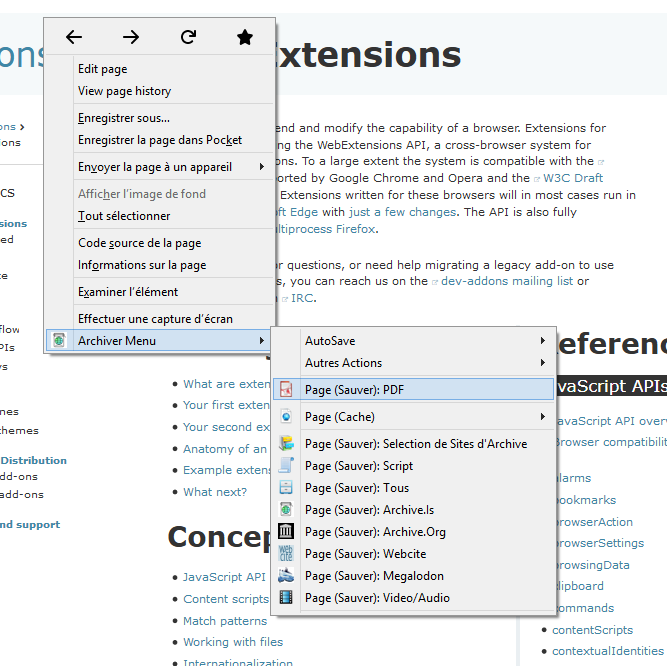
- 1.7 Menu Principal - Français
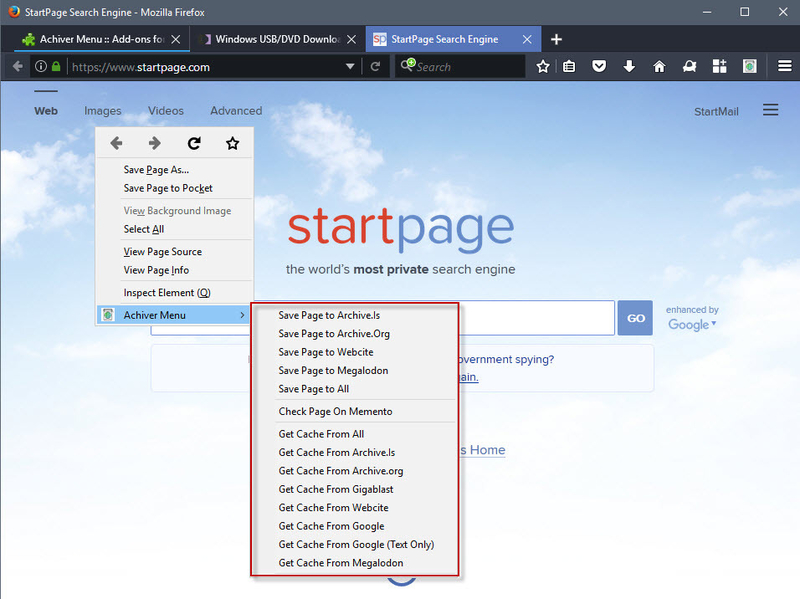


/http%3A%2F%2Fstorage.canalblog.com%2F24%2F21%2F1677815%2F132717263_o.jpg)